GPU架构学习
CUDA 编程模型和硬件模型对应

线程块中通过共享内存和寄存器相互通信协调,寄存器和共享内存的分配可以严重影响性能。
因为SM有限,虽然在编程模型看所有线程都是并行执行,但是在微观上看,所有线程也是分批次在物理层面的机器上执行,线程块(block)里不同的线程可能进度都不一样,但是同一个线程束的线程拥有相同的进度。
并行就会引起竞争,多线程以未定义的顺序访问同一个数据,就导致了不可预测的行为,CUDA只提供了一种块内(块内线程间)同步的方式,块之间没办法同步!
同一个SM上可以有不止一个常驻的线程束,有些在执行,有些在等待,他们之间状态的转换是不需要开销的。每个SM 都将 分配给它的线程块 划分到包含32个线程(我的理解,这32 个线程就是对应到SM硬件图中的core)的线程束中,然后在可用的硬件资源上调度执行。
Nvidia Fermi架构

解释:
Fermi架构
L2 Cache: 768 KB 的二级缓存,被所有SM共享;
DRAM: 6 个 384-bits 的GDRR5内存接口;
GigaThread引擎: 全局调度器,分配线程块到SM线程束调度器上;
SM(流多处理器器Stream Multiprocessor): 16个SM,每个SM支持数百个线程并发执行,当一个核函数的网格被启动的时候,多个block会被同时分配给可用的SM上执行。
SM
2 个 Warp(线程束): 采用单指令多线程 SIMT 架构管理执行线程,每个线程束中包括 16个Core, Warp编排器(Warp Scheduler),分发单元(Dispatch Unit);
Warp编排器(Warp Scheduler), 线程束调度器,
分发单元(Dispatch Unit), 指令调度(分配)单元,存储两个线程束要执行的命令,
寄存器文件(Register File)
16组加载存储单元(LD/ST)
4 个特殊函数单元(SFU) 执行固有指令,如正弦、余弦、平方根和差值
共享内存/一级缓存
CUDA核心
CUDA核心
一个 FP Unit: 浮点数运算单元FPU;
一个 INT Unit: 全流水线的整数算数逻辑单元 ALU;
SM 的中文对照:

Kepler 架构
是Fermi的后代
- 强化了SM
- 动态并行
- Hyper-Q 技术
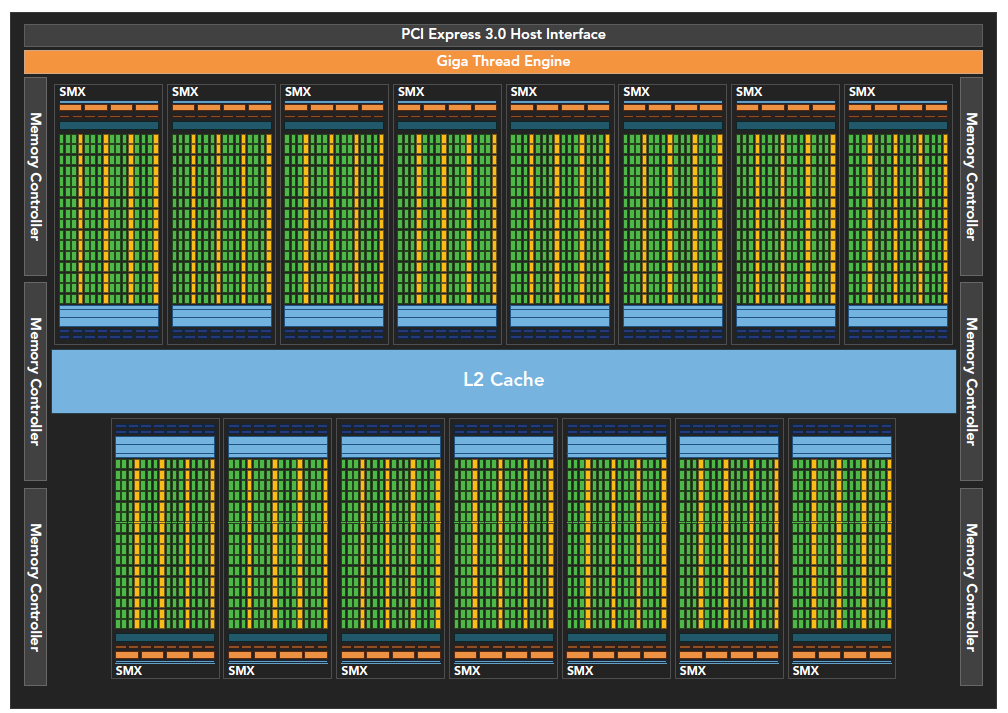

SMX是改进的架构,支持动态创建渲染线程,以降低延迟。
Hyper-Q技术主要是CPU和GPU之间的同步硬件连接,以确保CPU在GPU执行的同事做更多的工作。Fermi架构下CPU控制GPU只有一个队列,Kepler架构下可以通过Hyper-Q技术实现多个队列:

最后
想要优化速度,先要学好使用使用性能优化工具:
nvvp
nvprof
限制内核性能的主要包括但不限于y一下因素:
存储宽带
计算资源
指令和内存延迟